Performance consideration feedback
This chapter will provide you some useful information about the performance you should expect and about performance on production context (with big sized model and many users)
1. Reference time
You may wonder, if the performances you have are normal, that is, if the time elapsed, when doing usual action in Team for Capella, is the right one compared to what should be expected.
Ensuring that the elapsed time doing your actions is the expected one, will help you to ensure that there are no issues that could come from other cause like network lag, lack of memory, antivirus process etc..
1.1. Case Studies
Some studies have been done on reference Capella models:
-
The open source IFE model packaged with Capella
-
Combined IFEs, a modified version of IFE which is artificially swollen to have an important sized model.
The next figure presents some characteristics on those models and the expressions used to compute them.
| Characteristics | Project | ||
|---|---|---|---|
IFE |
Combined IFEs |
||
File (size in KB) |
|||
Project |
19 179 |
203 310 |
|
.capella |
1 475 |
13 464 |
|
.aird |
17 705 |
189 846 |
|
Model (number of elements) |
AQL expressions to use in Interpreter view |
||
Capella elements |
5 378 |
49 389 |
aql:self.eAllContents()→size() select the first child of the .aird file in the Project Explorer |
Components |
110 |
1 230 |
aql:self.eAllContents(cs::Component)→size() select the first child of the .aird file in the Project Explorer |
Functions |
224 |
2 652 |
aql:self.eAllContents(fa::AbstractFunction)→size() select the first child of the .aird file in the Project Explorer |
Diagrams |
111 |
880 |
aql:self.eResource().getContents()→filter(diagram::DDiagram)→size() select a diagram in the Project Explorer |
Tables |
1 |
8 |
aql:self.eResource().getContents()→filter(table::DTable)→size() select a diagram in the Project Explorer |
Elements displayed in all representations |
6 384 |
70 850 |
aql:self.eResource().getContents()→filter (viewpoint::DRepresentation).eAllContents (viewpoint::DRepresentationElement)→size() select a Diagram in the Project Explorer (only for local projects) |
Refer to How to get characteristics of your model to see how to get the characteristics of your own model in order to compare it with those reference models.
1.2. Measures
Measures contained in this document give some idea and order of magnitude of the performances expected for comparable environments.
They have been taken on two different deployments:
-
Local: single computer with both client and server - IFE and Combined IFEs
-
OVH: two virtual machines, one for the client and one for the server as recommenced in Deployment recommendations.
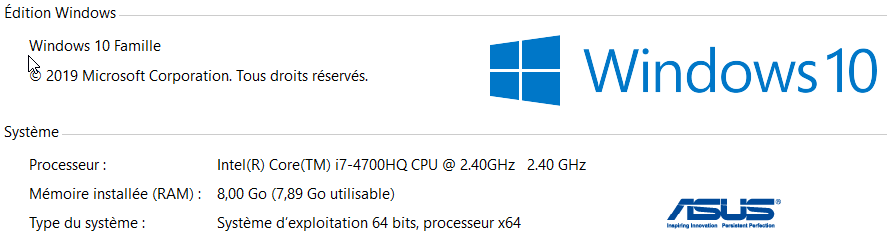
1.2.1. Computer used for the tests
Local Windows computer
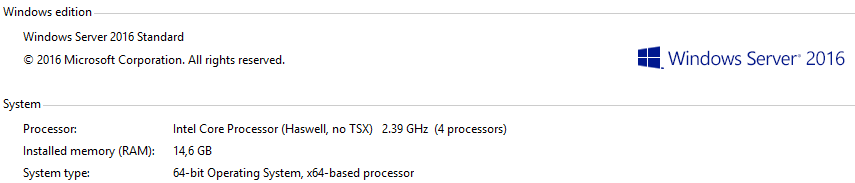
OVH Windows computer
1.2.2. Reference elapsed time
The memory allowed to the Team for Capella client can be configured with the capella.ini file beside capella.exe executable.
| Elapsed time (s) | IFE | Combined IFEs |
|---|---|---|
Xmx 3GB |
Xmx 3GB |
|
Export To Server |
28,7 |
114 |
Open Session (first time) |
3,7 |
9 |
Test Close Session |
1 |
3 |
Open Session |
2 |
6,5 |
Open the diagram (1) |
4 |
6 |
Create a LFBD diagram on Root Logical Function. (2) |
3 |
6 |
Save the session after steps from (3) |
2 |
7 |
1.3. Analysis and conclusion
The majority of the scenarios could be done with the minimum recommended memory of 3Go.
Nevertheless, with model of big size (Combined IFEs ), we need more RAM to work with constant performance for some actions like Refresh all representations or Validate on the whole model.
If the Team for Capella Client reaches, at execution, the maximum allowed memory, the performance may drastically fall particularly for actions that consume a lot of memory such as:
-
Import a Capella project locally from the server
-
Do the Validation of the whole project
-
Start Refresh All Representation action
-
Save if many objects have been changed or deleted
-
Some particular Capella functionality such as functional transition
2. Dedicated tests on Combined IFEs
The aim of this test session was to ensure that Team for Capella is able to have to keep the right performances after having used for a while.
-
Combined IFEs is used as the Capella Project. It is a large sized project.
-
20 users are connected to the Capella project on the server
-
8 users are really working on the model. During the test, they will do standard actions such as
-
Open many diagrams
-
Create, Refresh, modify diagrams
-
Make functional transition for some of them
-
Regularly create semantic element through diagram or not
-
Use tool in diagram palette
-
Use the Activity Explorer, F8 and F9 to navigate
-
Validate some parts of the model
-
But also, other actions that demands significant amount of RAM
-
The tests have been done with 21 virtual machines hosted on OVH cloud (20 clients and 1 server):
-
Client Xmx=3Go
-
Server Xmx=4Go
-
2.1. Server
Throughout the test, the server never reaches its maximum allowed memory of 4Go RAM and not even 3Go. It keeps constant performance.
2.2. Client
The client behaves constantly with good performance throughout the tests.
Nevertheless, the client may reach 3Go of memory if high memory consumption actions are performed such as:
-
Import a Capella project locally from the server
-
Do the Validation of the whole project
-
Start Refresh All Representation action
Once the maximum allowed memory is reached:
-
The user keeps having good performance for standard actions
-
But the performance may fall drastically for high memory consuming actions. For that cases, the performance issue can be solved
-
using more allowed memory for the client (Xmx=4 or more)
-
simply restarting the client
-
Note that the potential performance issue encountered by one user has no impact on another user
2.3. conclusion
The model used is what we consider as a medium-big sized model.
20 users are working on it.
-
The server 4Go is well fitted for the use
-
The client 3Go RAM is sufficient for most cases.It can be increased to have best performance when the user uses high memory consuming action
3. How to get characteristics of your model
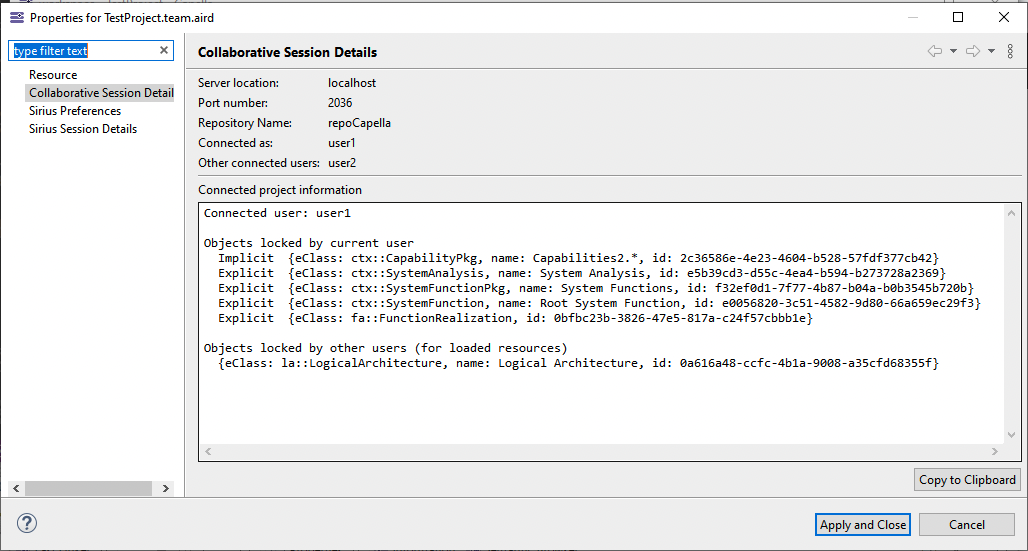
The simplest way to get characteristics of your model is to use the Sirius Session Details tab available in the Properties contextual menu of the .aird file of your project:
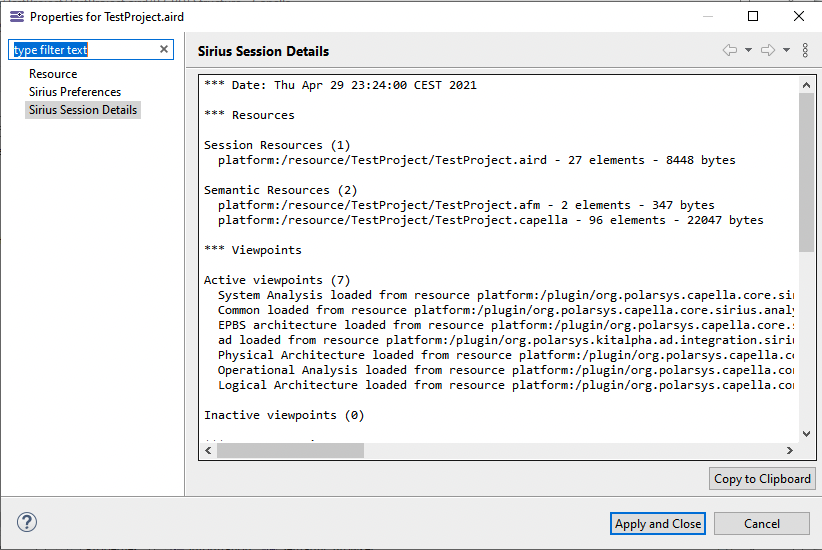
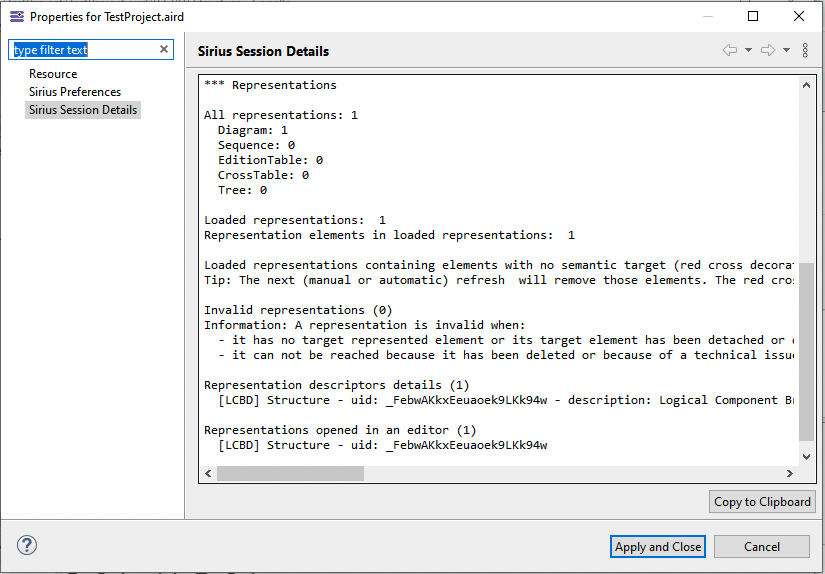
It will give you the following information about your project:
-
Number, name, path and number of contained elements of each resources
-
Selected Viewpoints
-
Number of representations
-
Some details about each representation (name type, id, status)
-
Number of loaded representations
-
Number of representations opened in editor
On shared projects, the Collaborative Session Details tab gives information about connected users and locks:
It is also possible to additional model characteristics thanks to the Interpreter view:
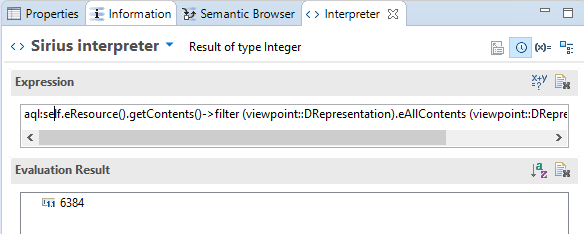
To get the characteristics of the .capella semantic resource :
-
select any semantic element

-
write the AQL query in the Interpreter view to get the result in the lower part of the view.
To get the characteristics of the representations in the .aird
-
select any representation
-
write the AQL query in the Interpreter view to get the result in the lower part of the view